The ChildRecordsR package is an R package dedicated to the analysis of annotations of daylong recordings in ChildRecordsData format. The objective of our package is to provide data aggregation functions and to analyze the reliability of annotations and annotators.
Create a ChildRecordings class
Here you will create a class by specifying the root folder of your corpus, which needs to be formatted using ChildRecordingData specifications. By using a class, we standardize all the references to the information in your corpus. Additionally, we provide basic checks such as missing files or unreferenced files in the meta data. Try to add, misplace or erase some files to see how these checks work.
library(ChildRecordsR)
ChildRecordingsPath = "/mnt/94707AA4707A8CAC/CNRS/corpus/namibia-data/"
CR = ChildRecordings(ChildRecordingsPath)
#> ###############################################
#> Hello Wellcome to the ChildRecordings R Project
#>
#> Your ChildRecording project path contained :
#> 3619 annotations files
#> 1559 are referenced in the metadata
#> 7 coders were found : textgrid/m1 alice_vtc vtc alice textgrid/ak textgrid/mm textgrid/ac
#>
#> 42 file(s) seem(s) to be unreferenced in the metadata
#> more infos in ChildRecordings$integrity_test$files.unreferenced
#>
#> 427 metadata don't have a start recording time (a.k.a start.time)
#> therefore time indicators will not be built for those files
#> more infos in ChildRecordings$integrity_test$missing.start.timeAll functions are based on the class (i.e., CR in our example above) to avoid problems of reference, since the class is always set up in the same way.
Finding annotations: Search function
Before it can provide any statistical reliability, the current package will need to find annotation segments that have been annotated by at least two annotators. The annotators could be humans or algorithms – the package does not know the difference, so you need to think about implications. This search is performed by the find.rating.segment function, which returns a data frame with the wav filenames, the annotators’ codenames, the annotation filenames and the onset and offset of the annotated segment(s) with respect to the wav.
At a minimum, you need to provide to the search function the class (i.e., CR in our example above) and the relative path to one or several wav files. The function will then find every segment annotated by any annotators in the wav files. In the following example, we provide the path to a single wav file (to speed things up, see section Analyze a corpus for an example with multiple files):
find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav")
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav alice_vtc
#> 4 aiku/namibie_aiku_20160715_1.wav alice
#> 5 aiku/namibie_aiku_20160715_1.wav vtc
#> 6 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 4 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 5 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 6 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000Alternatively, if a specific time window is provided, the search function will find all the annotations that overlap with the time window provided.
find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav",range_from = 27180000, range_to = 27240000)
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav alice_vtc
#> 4 aiku/namibie_aiku_20160715_1.wav alice
#> 5 aiku/namibie_aiku_20160715_1.wav vtc
#> 6 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 4 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 5 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 6 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav",range_from = 27000000, range_to = 27250000)
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav alice_vtc
#> 4 aiku/namibie_aiku_20160715_1.wav alice
#> 5 aiku/namibie_aiku_20160715_1.wav vtc
#> 6 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 4 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 5 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 6 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav",range_from = 27180000, range_to = 27260000)
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav alice_vtc
#> 4 aiku/namibie_aiku_20160715_1.wav alice
#> 5 aiku/namibie_aiku_20160715_1.wav vtc
#> 6 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 4 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 5 aiku/namibie_aiku_20160715_1_0_0.csv 27180000 27240000
#> 6 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000It is also possible to find annotations for a specific set of annotators, by providing the list of their codenames:
raters <- c("textgrid/ak","textgrid/mm","textgrid/m1")
find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav",raters)
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000Time window and limited annotator can also be specified jointly:
search1 <- find.rating.segment(CR,"aiku/namibie_aiku_20160715_1.wav", raters, range_from = 27180000, range_to = 27240000)
search1
#> recording_filename set
#> 1 aiku/namibie_aiku_20160715_1.wav textgrid/ak
#> 2 aiku/namibie_aiku_20160715_1.wav textgrid/m1
#> 3 aiku/namibie_aiku_20160715_1.wav textgrid/mm
#> annotation_filename true_onset true_offset
#> 1 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 2 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000
#> 3 aiku/namibie_aiku_20160715_1_27000000_180000.csv 27180000 27240000Measuring reliability and classification agreement
Once you have obtained information on a set of annotations with the search function and stored it in an object (search1 above), you can use the aggregate function. This function will create a table with the annotation information, and additionally convert your data into a long format, where annotations are split up into temporal bins. For instance, imagine that an annotator said FEM spoke between .5s and 1s of the wav file. This would be one row in the table format. To convert this to long format, a bin size (in seconds) can be provided using the cut argument. For instance, if you specify cut = .01, then that 500 millisecond vocalization by FEM becomes 50 rows, each representing 10 milliseconds of speech. By default cut is set to 0.1 second. The function will return a raterData class with the original format and a long format for every annotator.
rating1 = aggregate.rating(search1, CR, cut = 100)
#> number of annotators 3
#> length of recording annotation for each annotator 60000 ms or 0.01666667 hoursNext, an analysis function can be called. We provide several. They all assume you have at least two annotators. It could be two automated algorithms, two humans, or one automated and one human – this package does not treat these cases differently, so you should interpret results carefully.
The reliability or get.reliability function provides alpha, kappa and AC1 for the whole pool of annotators in your search (so this works even if you have 10 annotators). Reliability will be computed for every speaker category and a composite of all of them.
rez1 = get.reliability(rating1)
#> Reliability indicator by type
#>
#> # CHI
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8603105 0.8238272 0.20709 0.03999 (0.129,0.286)
#> 2 Fleiss' Kappa 0.8602329 0.8238272 0.20665 0.03999 (0.128,0.285)
#> 3 AC1 0.8602329 0.1761728 0.83034 0.01572 (0.799,0.861)
#> p.value w.name
#> 1 3.061751e-07 unweighted
#> 2 3.239348e-07 unweighted
#> 3 0.000000e+00 unweighted
#>
#>
#> # OCH
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8647451 0.6468141 0.61704 0.03176 (0.555,0.679)
#> 2 Fleiss' Kappa 0.8646700 0.6468141 0.61683 0.03176 (0.554,0.679)
#> 3 AC1 0.8646700 0.3531859 0.79077 0.01884 (0.754,0.828)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
#>
#>
#> # FEM
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8298227 0.5202290 0.64529 0.02448 (0.597,0.693)
#> 2 Fleiss' Kappa 0.8297282 0.5202290 0.64510 0.02448 (0.597,0.693)
#> 3 AC1 0.8297282 0.2398855 0.77599 0.01593 (0.745,0.807)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
#>
#>
#> # MAL
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.9201774 0.8991808 0.20826 0.05041 (0.109,0.307)
#> 2 Fleiss' Kappa 0.9201331 0.8991808 0.20782 0.05041 (0.109,0.307)
#> 3 AC1 0.9201331 0.1008192 0.91118 0.01078 (0.89,0.932)
#> p.value w.name
#> 1 4.120029e-05 unweighted
#> 2 4.274618e-05 unweighted
#> 3 0.000000e+00 unweighted
#>
#>
#> # composit
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.6269402 0.2406038 0.50874 0.01837 (0.473,0.545)
#> 2 Fleiss' Kappa 0.6267332 0.2406038 0.50847 0.01837 (0.472,0.545)
#> 3 AC1 0.6267332 0.1518792 0.55989 0.01760 (0.525,0.594)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweightedAnother possible way to investigate annotators is through classification indicators, such as precision, recall, and F-score. These can only be calculated for cases with exactly two annotators. The first annotator will be assumed as the “gold” annotator, so if you have a human and an automated annotator, or someone with more versus less experience, make sure you order them so that the more reliable annotator (more likely to be “gold”) is provided first.
ratercomp <- c("textgrid/ak","textgrid/m1")
get.classification(rating1,ratercomp)
#> Confusion matrix :
#>
#> textgrid/m1
#> textgrid/ak CHI FEM MAL OCH overlap silence
#> CHI 28 0 0 0 1 0
#> FEM 16 159 8 3 7 5
#> MAL 0 9 12 0 0 0
#> OCH 0 1 0 68 9 9
#> overlap 1 9 0 4 28 0
#> silence 17 30 7 12 1 157
#>
#>
#> STD by class :
#>
#> Class: CHI Class: FEM Class: MAL Class: OCH Class: overlap
#> Sensitivity 0.45161290 0.7644231 0.44444444 0.7816092 0.60869565
#> Specificity 0.99814471 0.9007634 0.98432056 0.9630350 0.97477477
#> Pos Pred Value 0.96551724 0.8030303 0.57142857 0.7816092 0.66666667
#> Neg Pred Value 0.94055944 0.8784119 0.97413793 0.9630350 0.96779964
#> Precision 0.96551724 0.8030303 0.57142857 0.7816092 0.66666667
#> Recall 0.45161290 0.7644231 0.44444444 0.7816092 0.60869565
#> F1 0.61538462 0.7832512 0.50000000 0.7816092 0.63636364
#> Prevalence 0.10316140 0.3460899 0.04492512 0.1447587 0.07653910
#> Detection Rate 0.04658902 0.2645591 0.01996672 0.1131448 0.04658902
#> Detection Prevalence 0.04825291 0.3294509 0.03494176 0.1447587 0.06988353
#> Balanced Accuracy 0.72487881 0.8325932 0.71438250 0.8723221 0.79173521
#> Class: silence
#> Sensitivity 0.9181287
#> Specificity 0.8441860
#> Pos Pred Value 0.7008929
#> Neg Pred Value 0.9628647
#> Precision 0.7008929
#> Recall 0.9181287
#> F1 0.7949367
#> Prevalence 0.2845258
#> Detection Rate 0.2612313
#> Detection Prevalence 0.3727121
#> Balanced Accuracy 0.8811574
#>
#>
#> STD macro indicators :
#>
#> type unweight weight
#> 1 Recall 0.6614857 0.7520799
#> 2 Precision 0.7481908 0.7667892
#> 3 F1 0.6852576 0.7450533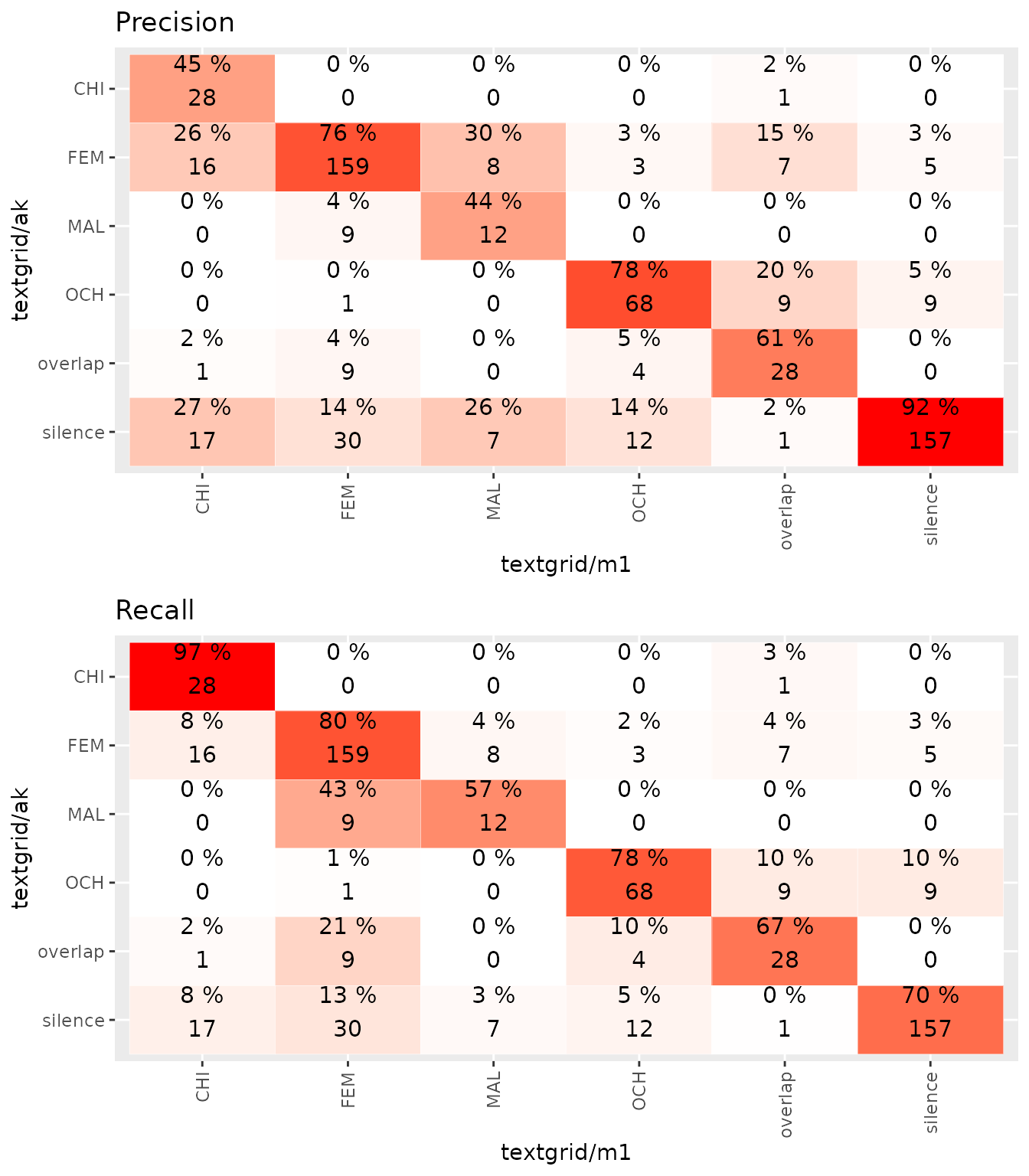
Compare annotators
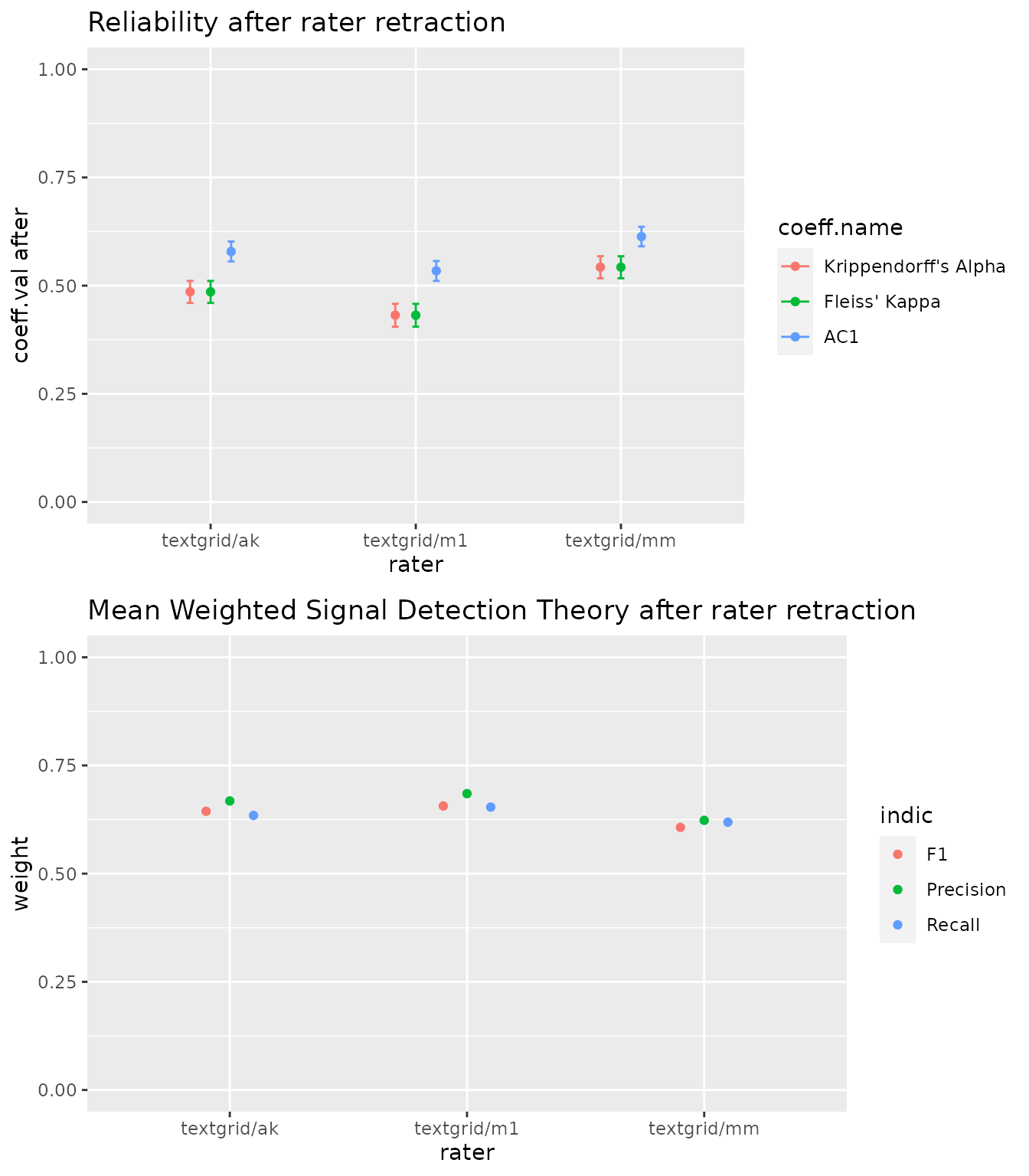
Finally, the raterComparaison function allows you to compare the impact of annotators on reliability indicators. This is useful if you have multiple human annotators and you want to check whether one of them is doing something different, or if you want to check whether your automated annotator stands out in your pool of annotators. You can only use this function when you have more than 2 annotators. The impact of a given annotator is calculated by removing that annotator from the pool of annotators, and observing the increase or decrease in the overall reliability. If the reliability indicators increase after the deletion of a specific annotator, then that annotator should be considered as having a negative impact on the annotations. In our next example, textgrid_mm has a negative impact on reliability.
comparaison = compare.rating(rating1)
#> number of annotators 3
#> length of reccording annotation 180000 seconds or 50 hours
#> Record span 60000 seconds or 16.66667 hours
#>
#> ### Annotator textgrid/ak ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.509 (0.473,0.545) 0.423
#> Fleiss' Kappa 0.508 (0.472,0.545) 0.423
#> AC1 0.560 (0.525,0.594) 0.473
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.375,0.472) 0.085
#> Fleiss' Kappa (0.374,0.472) 0.086
#> AC1 (0.425,0.52) 0.087
#>
#> unweight weight
#> Recall 0.549 0.663
#> Precision 0.602 0.658
#> F1 0.559 0.647
#>
#> ### Annotator textgrid/m1 ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.509 (0.473,0.545) 0.438
#> Fleiss' Kappa 0.508 (0.472,0.545) 0.438
#> AC1 0.560 (0.525,0.594) 0.498
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.389,0.487) 0.070
#> Fleiss' Kappa (0.389,0.487) 0.070
#> AC1 (0.451,0.545) 0.062
#>
#> unweight weight
#> Recall 0.613 0.653
#> Precision 0.564 0.665
#> F1 0.575 0.651
#>
#> ### Annotator textgrid/mm ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.509 (0.473,0.545) 0.667
#> Fleiss' Kappa 0.508 (0.472,0.545) 0.667
#> AC1 0.560 (0.525,0.594) 0.709
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.621,0.713) -0.158
#> Fleiss' Kappa (0.621,0.713) -0.158
#> AC1 (0.668,0.75) -0.149
#>
#> unweight weight
#> Recall 0.462 0.564
#> Precision 0.457 0.617
#> F1 0.449 0.582
plot(comparaison)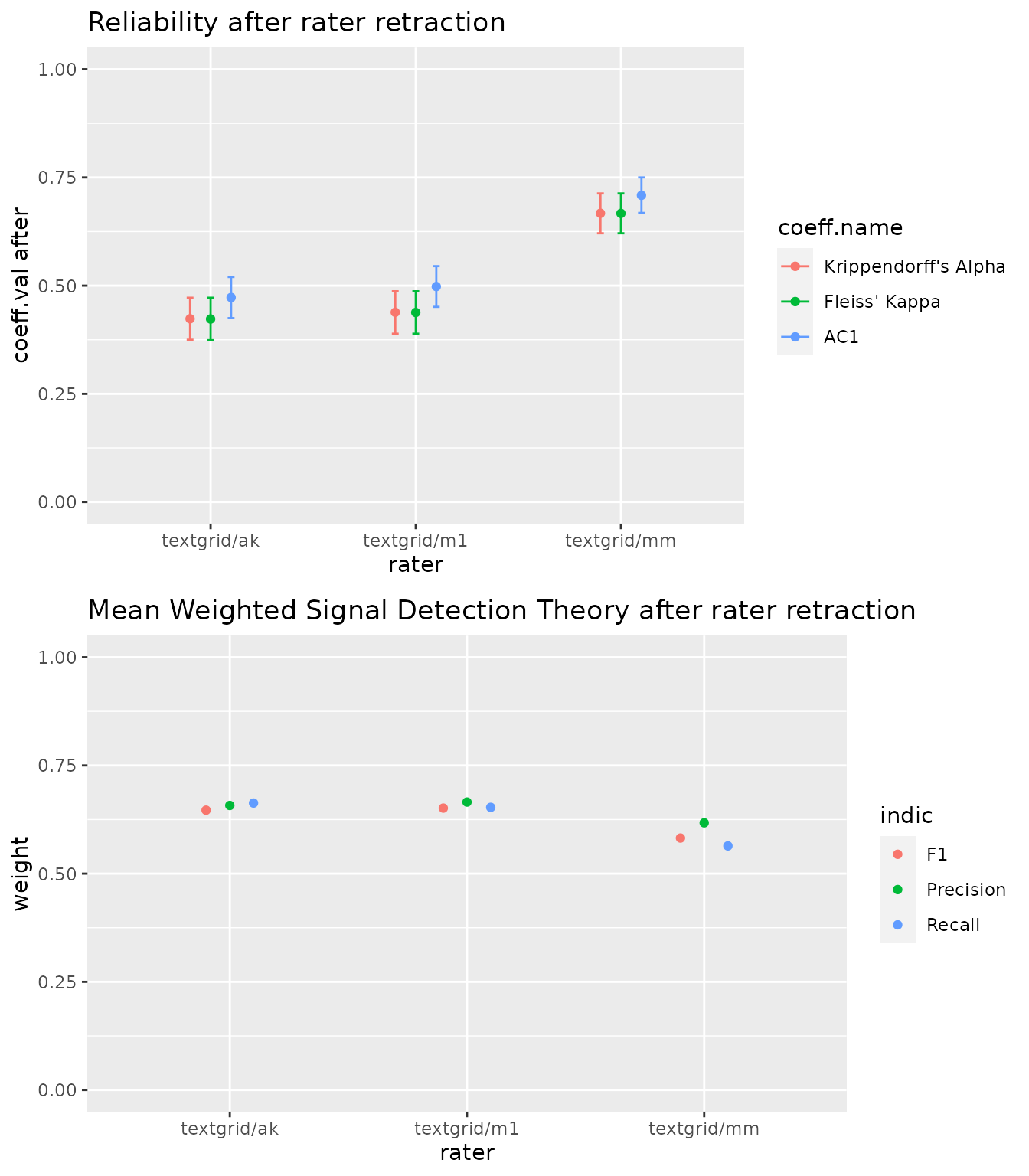
Corpus analysis
The previous examples used a path to a single wave file. Typical, in order to have a general idea of the annotations, the preceding analyses must be carried out on the whole corpus, and thus multiple wave files. This is the analysis we try in the present example. The result in this case confirms our previous conclusion, that the textgrid_mm annotator had a negative impact on reliability.
wave_file <- unique(CR$all.meta$recording_filename)[1:10] # get all the wav files
raters <- c("textgrid/ak","textgrid/mm","textgrid/m1") # Define raters you are interested in
# bind all the results
search2 <- data.frame()
for (file in wave_file){
search2 <- rbind(search2, find.rating.segment(CR, file, raters)) # could take some time
}
# aggregation
rating2 = aggregate.rating(search2,CR,100,verbose = F)
#> number of annotators 3
#> length of recording annotation for each annotator 240000 ms or 0.06666667 hours
rez2 = get.reliability(rating2)
#> Reliability indicator by type
#>
#> # CHI
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8455566 0.7436043 0.39764 0.01794 (0.362,0.433)
#> 2 Fleiss' Kappa 0.8455352 0.7436043 0.39755 0.01794 (0.362,0.433)
#> 3 AC1 0.8455352 0.2563957 0.79228 0.00926 (0.774,0.81)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
#>
#>
#> # OCH
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8590046 0.7481137 0.44024 0.01961 (0.402,0.479)
#> 2 Fleiss' Kappa 0.8589850 0.7481137 0.44016 0.01961 (0.402,0.479)
#> 3 AC1 0.8589850 0.1259431 0.83867 0.00681 (0.825,0.852)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
#>
#>
#> # FEM
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.8465271 0.5940295 0.62196 0.01393 (0.595,0.649)
#> 2 Fleiss' Kappa 0.8465058 0.5940295 0.62191 0.01393 (0.595,0.649)
#> 3 AC1 0.8465058 0.2029852 0.80741 0.00750 (0.793,0.822)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
#>
#>
#> # MAL
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.9564675 0.9510656 0.11039 0.03096 (0.05,0.171)
#> 2 Fleiss' Kappa 0.9564615 0.9510656 0.11027 0.03096 (0.05,0.171)
#> 3 AC1 0.9564615 0.0489344 0.95422 0.00370 (0.947,0.961)
#> p.value w.name
#> 1 0.0003697034 unweighted
#> 2 0.0003753318 unweighted
#> 3 0.0000000000 unweighted
#>
#>
#> # composit
#>
#> coeff.name pa pe coeff.val coeff.se conf.int
#> 1 Krippendorff's Alpha 0.6357965 0.2886934 0.48798 0.00994 (0.468,0.507)
#> 2 Fleiss' Kappa 0.6357460 0.2886934 0.48791 0.00994 (0.468,0.507)
#> 3 AC1 0.6357460 0.1422613 0.57533 0.00886 (0.558,0.593)
#> p.value w.name
#> 1 0 unweighted
#> 2 0 unweighted
#> 3 0 unweighted
comparaison = compare.rating(rating2)
#> number of annotators 3
#> length of reccording annotation 720000 seconds or 200 hours
#> Record span 240000 seconds or 66.66667 hours
#>
#> ### Annotator textgrid/ak ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.488 (0.468,0.507) 0.486
#> Fleiss' Kappa 0.488 (0.468,0.507) 0.486
#> AC1 0.575 (0.558,0.593) 0.579
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.46,0.511) 0.002
#> Fleiss' Kappa (0.46,0.511) 0.002
#> AC1 (0.556,0.602) -0.003
#>
#> unweight weight
#> Recall 0.524 0.635
#> Precision 0.504 0.668
#> F1 0.502 0.644
#>
#> ### Annotator textgrid/m1 ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.488 (0.468,0.507) 0.432
#> Fleiss' Kappa 0.488 (0.468,0.507) 0.432
#> AC1 0.575 (0.558,0.593) 0.534
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.405,0.458) 0.056
#> Fleiss' Kappa (0.405,0.458) 0.056
#> AC1 (0.511,0.557) 0.041
#>
#> unweight weight
#> Recall 0.565 0.654
#> Precision 0.537 0.685
#> F1 0.526 0.656
#>
#> ### Annotator textgrid/mm ###
#>
#> coeff.val before conf.int before coeff.val after
#> Krippendorff's Alpha 0.488 (0.468,0.507) 0.543
#> Fleiss' Kappa 0.488 (0.468,0.507) 0.543
#> AC1 0.575 (0.558,0.593) 0.613
#> conf.int after coeff.difference
#> Krippendorff's Alpha (0.517,0.568) -0.055
#> Fleiss' Kappa (0.517,0.568) -0.055
#> AC1 (0.591,0.636) -0.038
#>
#> unweight weight
#> Recall 0.461 0.619
#> Precision 0.509 0.623
#> F1 0.460 0.607
plot(comparaison)